NTT DATA’s recent survey of business leaders around the world revealed 96% of all 2300+ respondents place a growing emphasis on GenAI’s long-term potential and 97% of CEOs anticipate a material impact from GenAI technology. For those of us working with CxOs to drive business value from GenAI solutions, the results are consistent with what we find on the ground. There is however a good deal of variation – which puts me in mind of William Gibson’s quote “the future is already here – it's just not evenly distributed”.
Todays technology
Retrieval augmented generation (RAG) solutions are increasingly common - indeed many of the Generative AI case studies you will find on NTT DATA’s website have RAG at their heart. RAG solutions simply allow you to use the power of a large language model over a set of documents or text which - generally speaking - you control and curate. This means chatbots and other generative solutions give high quality results and rarely if ever hallucinate - because the source information is highly controlled. One common use case is customer self-service - allowing users to get the answers they need quickly and conveniently without having to read every document on your website. The success of these kinds of solutions is why CEOs in our survey are so optimistic - they are providing value today.
The unhappy path of knowledge management
But what happens when the source knowledge is not neatly presented - for example information overlaps, is inconsistent, has multiple versions which are true at different times or has diagrams which are not explained in the text? This is common in most organisations - knowledge management is far from perfect. One example close to my world is the documentation of the corporate IT estates, which typically features all these challenges. Moreover, architects commonly use graphical notation systems (formal diagrams) which are parsimonious, but not easily searchable.
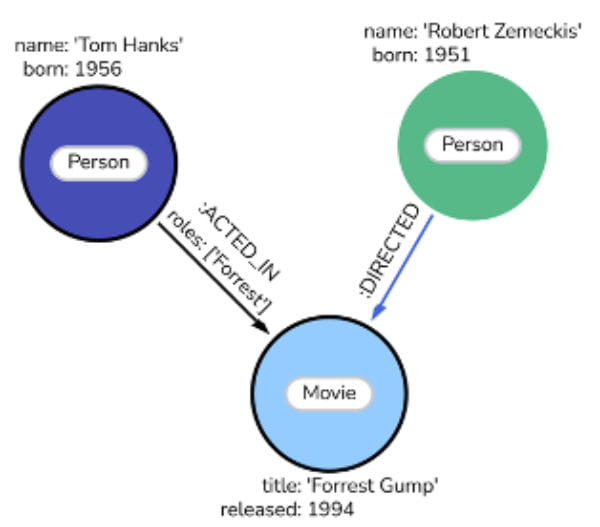
The answer to this problem has been around for years - enterprise architecture tools hold all this knowledge in a structured and re-usable way. There are typically a few problems however: 1) no tool is a panacea and their capabilities overlap meaning the corporate metadata is instantly fragmented and there is seldom one place to look 2) they are expensive so organisations limit access 3) in 25 years working in IT I’ve only seen one organisation get close to complete coverage (and they military in nature) - hence adoption is very patchy. With low coverage, the usefulness is limited. These tools have an interesting feature however - they are backed by knowledge graphs. A knowledge graph is simply a way of structuring any information into a set of nodes and ‘edges’ (relationships) - a simple example relating to one of my favourite films is shown below.
The client problem
Enter our moonshot problem. Given that IT knowledge was contained in architecture documents, our customer - Virgin Media O2 - (VMO2) wondered whether generative AI could take this knowledge and produce new designs based on new user stories. Inspired by the way this problem is solved in EA tools, we recognised that if we could create a knowledge graph of the existing design materials we would be part way there. Until the advent of generative AI, I had only input structured data into knowledge graphs. However large language models allow the nodes and edges of a graph to be lifted from documentation. If you know what you’re doing, multi-modal AI does a surpassingly good job of describing graphics and diagrams and modern graph databases such as Neo4J allow us to store vectors (the references that power RAG solutions) inside the graph. By using the graph together with RAG straight away allowed us to ask questions of the knowledge base that yielded significantly better answers. To put this in perspective: competing approaches which used RAG-only solutions were abandoned because the results were not useful in this complex scenario.
The original moonshot ask was an order of magnitude more difficult again. This required a third piece of modern gen AI technology: the agent. Agents work with specific remits and different instructions. The design document generator requires many agents, some of which work iteratively, critiquing each other’s work until the result is acceptable. It is no wonder people anthropomorphise Gen AI solutions - it’s like watching a human team at work - communicating in English - just in a fraction of a second (and they don’t need a Christmas party).
The title of this blog has given away the ending: we produced a design document which was rated as a ‘great start’ in a blind test. Have we eliminated architects from the design process? Of course not - and a good thing too as this is how I earn my living. However, we think consecutively these two tools will cut down design time by 20%. But the most exiting thing is not helping fellow architects with some frustrating parts of the job (“how much of this do I have to read to work out what’s going on?” “how can I know if the reviewer will be happy?”) but the application of this to any knowledge management problem where the underlying information is fragmented. That might be complex infrastructure, managing hospitals or homologation of a new car model.
For now we’re delighted to have our first happy customer - Sergio Rubio, head of Solution Architecture at VM02 “This proof of concept has already delivered impressive results, with real promise for transforming our approach to Solution Architecture. It’s driving up productivity, enhancing the quality of our deliverables, and ultimately enabling faster delivery across the board. A huge part of this success comes down to the fantastic collaboration with NTT Data, alongside Neo4J and AWS. Their team dove deep into our unique challenges and worked closely with us to push the boundaries of innovation. This partnership has been pivotal in showing us what’s possible as we move forward.”.
More to come
I’m sometimes asked: why does graph + RAG work so well? How do we deal with conflicting documents and versioning? How do I know if I need a graph or whether RAG alone will suffice? This is the introductory blog - the forthcoming whitepaper and podcast will explain more. Meanwhile if you have a non-trivial knowledge management problem - perhaps RAG solutions haven’t worked for you - get in touch.
Never stop shooting for the moon.